HAProxy w zastosowaniach - wstęp
Słowo klucz na najbliższe wpisy to rozwiązanie HAProxy - wysoko wydajny, dostępny serwer proxy zarówno dla połączeń TCP jak i HTTP . Cykl ten nie będzie stanowić kompletnego podręcznika opisującego HAProxy bo takowy już istnieje na stronie głównej projektu, będzie to raczej zbiór praktycznych zastosowań. Nie obejdzie się jednak bez wstępu i przybliżenia narzędzia.
Mając do dyspozycji kilka serwerów WWW, serwujących ten sam content sytuacja wymaga on nas administratorów zapewnienia wysoko dostępnej i wydajnej architektury. Swoją przygodę w tej dziedzinie rozpocząłem od popularnego LVS’a [1]. Rozwiązanie to w trybie pracy DR [2] zapewniało bardzo wysoką wydajność, zaś jako narzędzia zarządzającego tablicą wirtualnych serwerów (IPVS) pomiędzy , którymi rozkładano połączenia posłużył mi keepalived [3]. Rozwiązanie to pracuję na warstwie 4 modelu ISO/OSI w związku z tym de facto nie miało pojęcia na temat istnienia protokołu HTTP działającego na warstwie 7. Niosło to ze sobą szereg ograniczeń m.in. w postaci braku łatwego przekierowywania ruch ze względu na zawartość (strony statyczne vs dynamiczne) oraz braku systemu kolejkowania połączeń, który by zapobiegał tzw. efektowi kuli śnieżnej. To skłoniło mnie do poszukiwań innego/lepszego rozwiązania, tym sposobem natrafiłem na HAProxy [4] . Co zatem wyróżnia to rozwiązanie:
- oparty na licencji GPL
- wydajny (patrz. splice,kqueue,epoll)
- zapewnia load-balancing
- zaawansowane ACL’ki
- uniwersalny nie tylko HTTP a także inne rozwiązania na protokole TCP
- lekki, posiada tylko feature’y związane z proxy’owaniem połączeń bez przeładowanego panelu zarządzania, monitorowania, raportowania etc.
Konfiguracja sprowadza się do jednego pliku, podzielonego na sekcje:
- globalna jej ustawienia odnoszą się bardzo często do ustawień samego procesu haproxy w tym chroot,użytkownika z prawami, którego działa etc.
- defaults parametry domyślne dla wszystkich innych sekcji
- frontend najczęściej zawiera parametry związane z adresami IP, na których usługa nasłuchuje przychodzące połączenia
- backend serwery, które obsługując przychodzące połączenia
- listen zawiera kompletną definicję sekcji frontend plus sekcji backend, często wykorzystywaną dla definiowania ruchu TCP
Do zilustrowania wspomnianych sekcji najlepiej posłuży przykład:
:::text
global
daemon
user haproxy
group haproxy
pidfile /var/run/haproxy.pid
stats socket /var/run/haproxy.stat uid 100 gid 102 mode 600
defaults
mode http
maxconn 4096
timeout client 60s
timeout server 60s
timeout queue 40s
timeout connect 4s
timeout http-request 5s
option http-server-close
option abortonclose
balance roundrobin
option forwardfor
retries 2
frontend public
bind *:80
acl static_content url_reg .*\.(jpg|gif|png|js|css|pdf|html|flv|ico|swf)$
use_backend static if static_content
default_backend dynamic
backend dynamic
option httpchk OPTIONS * HTTP/1.1\r\nHost:\ default
server www1 10.1.0.2:80 maxconn 30 check port 80 weight 20
server www2 10.1.0.3:80 maxconn 30 check port 80 weight 20
server www3 10.1.0.5:81 maxconn 25 check port 80 weight 20 backup
backend static
option httpchk OPTIONS * HTTP/1.1\r\nHost:\ default
server www1 10.1.0.6:80 maxconn 100 check port 80 weight 20
server www2 10.1.0.7:80 maxconn 100 check port 80 weight 20 backup
listen stats
bind 127.0.0.1:7654
stats enable
stats hide-version
stats uri /
stats realm stats
w sekcji global ciekawą opcją jest opcja stats socket tworzy ona socket, do którego możemy się podłączyć netcat’em lub socat’em w celu zbierania statystyk lub sterowania dostępnością serwerów sekcji backend.
W sekcji default mamy szereg opcji timeout oraz istotną opcje http-server-close. HAProxy do serii 1.4 nie wspierał keep-alive po stronie klienta zatem każdy request wymagał ustanowienia na nowo połączenia TCP, zwiększało to niestety opóźnienia. Seria 1.4 wprowadza parametr http-server-close, dzięki czemu możliwy jest tryb keep-alive, ale tylko po stronie klienta. Kolejny istotny parametr to balance roundrobin to nic innego jak zwykły loadbalancing. W przypadku zastosowania serwera PROXY adres klienta jest podmieniany na adres serwera PROXY, w celu wydobycia adresu klienta wymagane jest jego podanie w nagłówku X-Forwarded-For do tego służy parametr forwardfor. Serwer Apache jest w stanie podmienić adres klienta z pola X-Forwarded-For przy zastosowaniu modułu mod_rpaf [5] . Dodatkowo opcja mode http definiuje tryb pracy HAProxy
W sekcji frontend ciekawym zabiegiem jest skorzystanie z rozbudowanych ACL’i w celu wydobycia z adresu request’u plików statycznych i skojarzeniu ich z backend’em static zamiast domyślnym dynamic.
W sekcji backend mamy zdefiniowane adresy serwerów wraz z opcją w jaki sposób ma być badana ich dostępność (httpchk). Istotnym parametrem w sekcji serwerów jest parametr maxconn, określa on ile dany serwer może przetwarzać jednocześnie request’ów, nadmiarowe połączenia zostaną skolejkowane. W przypadku wymagających aplikacji parametr ten nie powinien być ustawiony na zbyt wysoki bo doprowadzić to może nadmiernego obciążenia www co w ostateczności obniżyć może jego czas odpowiedzi, parametr ten wymaga indywidualnego doboru. Parametr weight służy do określenia wagi serwera w przypadku rozkładania połączeń na wiele serwerów, parametr backup służy do zdefiniowania serwera, który ma zastąpić niedostępny serwer.
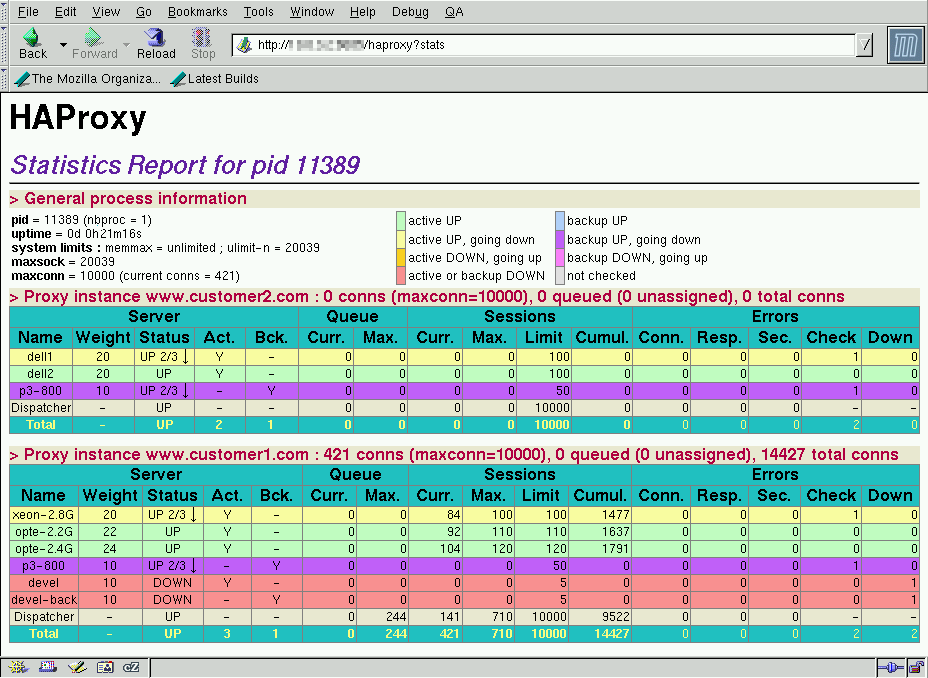
W sekcji listen zdefiniowane są parametry służące do połączenia się ze stroną www prezentującą statystki działania serwera. Przykładową taką stronę znajdziemy pod adresem http://haproxy.1wt.eu/img/haproxy-stats.png. Prócz informacji o liczbie przetworzonych request’ów oraz dostępności poszczególnych serwerów, istotnym parametrem jest również wykorzystanie kolejki. W przypadku poprawnie określonych parametrów maxconn dla serwerów, przepełniająca się kolejka jest pierwszych sygnałem, że w naszej architekturze pojawia się wąskie gardło.
{kind=link}
[1] http://www.linuxvirtualserver.org/
[2] http://kb.linuxvirtualserver.org/wiki/LVS/DR
powered by Hugo and Noteworthy theme